The node iterator interface is defined in
org.apache.xalan.xsltc.NodeIterator.
The most basic operations in the NodeIterator interface are
for setting the iterators start-node. The "start-node" is
an index into the DOM. This index, and the axis of the iterator, determine
the node-set that the iterator contains. The axis is programmed into the
various node iterator implementations, while the start-node can be set by
calling:
 | | |
|
public NodeIterator setStartNode(int node); | |
| | |
Once the start node is set the node-set can be traversed by a sequence of
calls to:
This method will return the constant NodeIterator.END when
the whole node-set has been returned. The iterator can be reset to the start
of the node-set by calling:
| | |
|
public NodeIterator reset(); | |
| | |
Two additional methods are provided to set the position within the
node-set. The first method below will mark the current node in the
node-set, while the second will (at any point) set the iterators position
back to that node.
| | |
|
public void setMark();
public void gotoMark(); | |
| | |
Every node iterator implements two functions that make up the
functionality behind XPath's getPosition() and
getLast() functions.
| | |
|
public int getPosition();
public int getLast(); | |
| | |
The getLast() function returns the number of nodes in the
set, while the getPosition() returns the current position
within the node-set. The value returned by getPosition() for
the first node in the set is always 1 (one), and the value returned for the
last node in the set is always the same value as is returned by
getLast().
All node iterators that implement an XPath axis will return the node-set
in the natural order of the axis. For example, the iterator implementing the
ancestor axis will return nodes in reverse document order (bottom to
top), while the iterator implementing the descendant will return
nodes in document order. The node iterator interface has a method that can
be used to determine if an iterator returns nodes in reverse document order:
| | |
|
public boolean isReverse(); | |
| | |
Two methods are provided for when node iterators are encapsulated inside
a variable or parameter. To understand the purpose behind these two methods
we should have a look at a sample XML document and stylesheet first:
| | |
|
<?xml version="1.0"?>
<foo>
<bar>
<baz>A</baz>
<baz>B</baz>
</bar>
<bar>
<baz>C</baz>
<baz>D</baz>
</bar>
</foo>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="foo">
<xsl:variable name="my-nodes" select="//foo/bar/baz"/>
<xsl:for-each select="bar">
<xsl:for-each select="baz">
<xsl:value-of select="."/>
</xsl:for-each>
<xsl:for-each select="$my-nodes">
<xsl:value-of select="."/>
</xsl:for-each>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet> | |
| | |
Now, there are three iterators at work here. The first iterator is the
one that is wrapped inside the variable my-nodes - this
iterator contains all <baz/> elements in the
document. The second iterator contains all <bar>
elements under the current element (this is the iterator used by the
outer for-each loop). The third and last iterator is the one
used by the first of the inner for-each loops. When the outer
loop is run the first time, this third iterator will be initialized to
contain the first two <baz> elements under the context
node (the first <bar> element). Iterators are by default
restarted from the current node when used inside a for-each
loop like this. But what about the iterator inside the variable
my-nodes? The variable should keep its assigned value, no
matter what the context node is. In able to prevent the iterator from being
reset, we must use a mechanism to block calls to the
setStartNode() method. This is done in three steps:
- The iterator is created and initialized when the variable gets
assigned its value (node-set).
- When the variable is read, the iterator is copied (cloned). The
original iterator inside the variable is never used directly. This is
to make sure that the iterator inside the variable is always in its
original state when read.
- The iterator clone is marked as not restartable to prevent it from
being restarted when used to iterate the
<xsl:for-each>
element loop.
These are the two methods used for the three steps above:
| | |
|
public NodeIterator cloneIterator();
public void setRestartable(boolean isRestartable); | |
| | |
Special care must be taken when implementing these methods in some
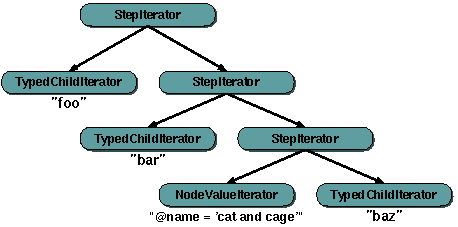
iterators. The StepIterator class is the best example of this.
This iterator wraps two other iterators; one of which is used to generate
start-nodes for the other - so one of the encapsulated node iterators must
always remain restartable - even when used inside variables. The
StepIterator class is described in detail later in this
document.